
La ciencia avanza a un ritmo vertiginoso. Cada año, se publican cientos de miles de artículos en revistas especializadas, y mantenerse al día con esta enorme cantidad de información es un reto prácticamente inabarcable. La tarea de procesar e integrar todos esos nuevos conocimientos supera las capacidades de los investigadores, y eso hace que cuestiones importantes a veces puedan pasar desapercibidas.
Para afrontar este enorme desafío, algunos investigadores se están apoyando en la inteligencia artificial. En áreas como la biología molecular o el descubrimiento de fármacos, las herramientas computacionales ya han revolucionado la forma en que se procesan y analizan datos complejos. Pero, ¿podría la inteligencia artificial no solo ayudar a analizar información existente, sino también predecir los resultados científicos aún no realizados?
En un estudio reciente publicado en Nature Human Behaviour, la investigadora Guiomar Niso, directora del Grupo de Neuroimagen del Instituto Cajal del CSIC, ha explorado esta posibilidad en el campo de la neurociencia. Junto a investigadores de distintas instituciones, evaluaron si los grandes modelos de lenguaje, conocidos como LLMs (Large Language Models), pueden predecir los resultados de experimentos científicos mejor que los propios expertos humanos. Los resultados fueron sorprendentes: la inteligencia artificial no solo fue más precisa que los expertos científicos, sino que también reveló un enorme potencial para acelerar el ritmo del descubrimiento científico.
Los modelos de lenguaje y su capacidad de predicción en neurociencia
Los grandes modelos de lenguaje (LLMs) son sistemas de inteligencia artificial diseñados para comprender y generar texto. Se entrenan con enormes cantidades de datos, desde libros hasta artículos científicos, y una vez entrenados pueden reconocer patrones, resumir información y responder preguntas con una precisión impresionante. Modelos como ChatGPT, Gemini, Deepseek han demostrado gran habilidad en tareas como aprobar exámenes profesionales, resolver problemas matemáticos complejos e incluso generar código de programación. Hasta ahora, estos modelos se han utilizado principalmente para recuperar información sobre hechos pasados. Sin embargo, se planteó una pregunta novedosa: ¿podrían los LLMs predecir los resultados de experimentos científicos antes de que estos se lleven a cabo?
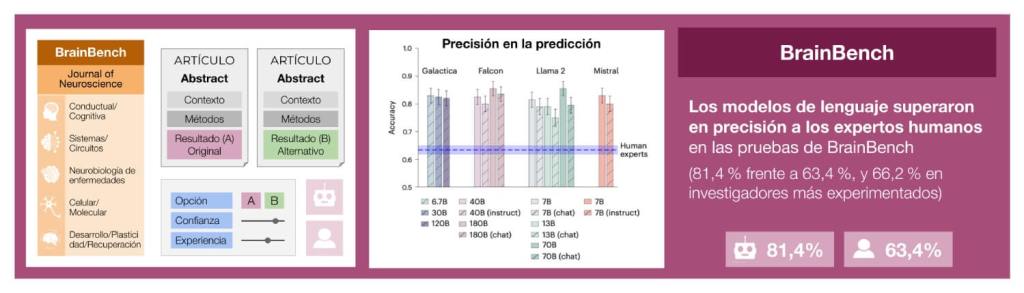
Para responder a esta pregunta, Guiomar Niso, junto a un equipo de investigadores liderados por Xiaoliang Luo y Bradley C. Love de la University College London, desarrollaron BrainBench, un banco de pruebas diseñado para evaluar la capacidad de los LLMs para predecir hallazgos científicos. A diferencia de otros sistemas de evaluación, BrainBench no mide la capacidad de los modelos para recuperar información o razonar basándose en datos conocidos (lo que se conoce como "backward-looking" o retrospección), sino que mide la habilidad del modelo para inferir el resultado de un experimento en función de su diseño y metodología (lo que llamaríamos "forward-looking" o prospección).

El experimento realizado consistió en presentar resúmenes de artículos recientes del Journal of Neuroscience en dos versiones: una con los resultados originales del estudio y otra con resultados modificados de forma coherente, pero incorrecta. Tanto los modelos de inteligencia artificial como un grupo de más de 200 expertos en neurociencia, compuesto por científicos, profesores e investigadores predoctorales y postdoctorales, debían elegir cuál de las dos versiones de los resúmenes presentados era la correcta.
Para construir BrainBench, los investigadores utilizaron 200 test creados por expertos humanos y 100 generados por GPT-4, garantizando que todos los casos pasaran controles de calidad para asegurar su coherencia. La versión alterada de los resúmenes se diseñó para cambiar significativamente los resultados sin modificar la metodología o el contexto del estudio, asegurando que la decisión dependiera de la comprensión de los datos y no de un simple reconocimiento de patrones lingüísticos.
Los artículos incluidos en BrainBench cubrieron las principales áreas de la neurociencia, incluyendo la neurociencia del comportamiento y cognitiva, la neurociencia de sistemas y circuitos, la neurobiología de enfermedades, el desarrollo, la plasticidad y la reparación, así como la neurociencia celular y molecular.
Para evaluar el rendimiento de los modelos, se utilizó una métrica llamada perplejidad, que mide el nivel de sorpresa o incertidumbre de un modelo ante un texto dado. Cuanto menor sea la perplejidad, mayor será la confianza del modelo en su respuesta, puesto que el resultado es más predecible. En este estudio, los LLMs eligieron entre las dos versiones de los resúmenes comparando sus niveles de perplejidad: la versión con menor perplejidad fue considerada como la respuesta más probable. Esto permitió cuantificar con precisión su capacidad predictiva y comparar sus resultados con los de los expertos humanos.
Los resultados fueron impactantes. Mientras que los expertos humanos lograron una precisión del 63,4%, los grandes modelos de lenguaje alcanzaron un 81,4%. Incluso los investigadores más experimentados no superaron el 66,2% de aciertos, quedando por debajo del rendimiento de los LLMs en todos los subcampos de la neurociencia analizados.
BrainGPT: un modelo especializado para la neurociencia
El estudio también exploró si un modelo LLM general podía mejorarse aún más mediante un ajuste específico para la neurociencia. Para ello, el equipo de investigadores desarrollamos BrainGPT, una versión optimizada del modelo Mistral-7B, que fue entrenada con más de 1,3 mil millones de palabras extraídas de artículos científicos en neurociencia publicados entre 2002 y 2022.
Para adaptar el modelo sin necesidad de reentrenarlo desde cero, se utilizó una técnica llamada LoRA (Low-Rank Adaptation). LoRA permite especializar un modelo LLM sin modificar todos sus parámetros, añadiendo solo pequeñas modificaciones en áreas clave del sistema. Gracias a este método, BrainGPT mejoró su precisión en BrainBench en un 3% adicional, lo que demuestra que afinar los LLMs con literatura científica específica puede hacerlos aún más eficaces para tareas concretas.
El desarrollo de BrainGPT plantea una posibilidad fascinante: que en el futuro, modelos especializados en distintas áreas del conocimiento puedan actualizarse casi en tiempo real con los últimos avances científicos. De hecho, el estudio sugiere que tecnologías como retrieval-augmented generation, que permiten a los modelos consultar bases de datos de artículos recientes, podrían hacer que herramientas como BrainGPT se mantuvieran constantemente actualizadas.
¿Cómo logran los LLMs superar a los humanos?
El éxito de los modelos de inteligencia artificial en este estudio puede deberse a varios factores. En primer lugar, su capacidad para procesar grandes volúmenes de información es incomparable. Mientras que un investigador puede leer cientos de artículos a lo largo de su carrera, un LLM ha sido entrenado con cientos de miles de estudios, lo que le permite detectar correlaciones y tendencias que un humano podría pasar por alto.
Otro aspecto fundamental es que los modelos son capaces de identificar patrones en datos dispersos. La neurociencia es un campo especialmente difícil de predecir porque abarca múltiples niveles de análisis, desde el comportamiento hasta los mecanismos moleculares del cerebro. Además, los resultados de un experimento pueden ser contradictorios o difíciles de replicar, lo que complica la interpretación de los hallazgos. Sin embargo, los LLMs pueden integrar información de diversas fuentes y reconocer relaciones subyacentes que dan lugar a predicciones más acertadas.
Un hallazgo particularmente interesante del estudio es que los LLMs calibran bien su confianza. Cuando un modelo estaba seguro de su predicción, tenía muchas más probabilidades de acertar. Esta capacidad de autoevaluación es crucial para que los científicos puedan confiar en sus sugerencias y combinar el juicio humano con la potencia de la inteligencia artificial.

¿Un complemento para la ciencia o una amenaza?
El uso de herramientas como BrainGPT plantea una cuestión importante: ¿deberían los científicos confiar en la inteligencia artificial para guiar sus investigaciones? En un futuro cercano, estos modelos podrían utilizarse para formular hipótesis más precisas, optimizar el diseño de experimentos y predecir qué líneas de investigación tienen más probabilidades de éxito. Sin embargo, esta tecnología también conlleva riesgos. Uno de los mayores temores es que los investigadores puedan descartar estudios que, aunque la inteligencia artificial los estimase como improbables, podrían conducir a descubrimientos revolucionarios. Además, existe el riesgo de que los LLMs amplifiquen sesgos presentes en la literatura científica, lo que podría consolidar errores o prejuicios ya existentes. También se corre el peligro de que se prioricen estudios más convencionales sobre otros más arriesgados pero potencialmente innovadores, simplemente porque los modelos de inteligencia artificial consideran que estos últimos son menos probables.
El estudio también señala que, aunque los LLMs son herramientas poderosas, la interpretación sigue siendo esencial. Un modelo puede predecir un resultado con alta precisión, pero la explicación de por qué sucede algo sigue siendo responsabilidad de los científicos. En este sentido, la inteligencia artificial podría cambiar la manera en que se formula la ciencia, pero el pensamiento crítico humano seguirá siendo insustituible.

Conclusión: una nueva era para la investigación científica
El estudio publicado en Nature Human Behaviour marca un antes y un después en el uso de la inteligencia artificial en la investigación científica. Por primera vez, se ha demostrado que los grandes modelos de lenguaje pueden no solo recuperar información, sino también anticipar nuevos descubrimientos con una precisión realmente alta.
A medida que esta tecnología evoluciona, es probable que se convierta en una aliada indispensable para los científicos, ayudando a acelerar la generación de conocimiento y a hacer la ciencia más eficiente. Sin embargo, su éxito dependerá de cómo se integre con el trabajo humano y de las medidas que se adopten para garantizar que su uso sea ético y responsable. Si se aprovecha correctamente, la sinergia entre humanos y máquinas podría abrir la puerta a una nueva era de descubrimientos científicos más rápidos, precisos y transformadores.
Referencias
- Luo, X., Rechardt, A., Sun, G., Nejad, K. K., Yáñez, F.... Niso, G.... & Love, B. C. (2024). Large language models surpass human experts in predicting neuroscience results. Nature Human Behaviour, 1-11. doi: 10.1038/s41562-024-02046-9. Preprint (2024): https://arxiv.org/abs/2403.03230

Julia Guiomar Niso Galán
Directora del Grupo de Neuroimagen del Instituto Cajal, CSIC y miembro de la Academia Joven de España.




