
La descripción de imágenes por IA involucra la interpretación y generación de texto que explica o comenta sobre el contenido visual de una imagen. Este proceso utiliza tecnologías como el procesamiento del lenguaje natural (PLN) y la visión por computadora. El objetivo es crear descripciones precisas y contextuales que sean útiles para los usuarios, particularmente para aquellos con discapacidades visuales.
Importancia de la descripción de imágenes mediante IA
Procesamiento del lenguaje natural y visión por computadora
El procesamiento de lenguaje natural o PLN permite que la IA comprenda y utilice el lenguaje humano para generar descripciones coherentes y contextualmente apropiadas.
Redes Neuronales Convolucionales para la identificación de patrones
Utilizadas en la visión por computadora, las redes neuronales convolucionales o CNN pueden identificar patrones y características en imágenes, facilitando su clasificación y descripción
Modelos de atención y su relevancia en descripciones
Estos modelos ayudan a la IA a enfocarse en partes específicas de la imagen al generar descripciones, mejorando la relevancia y precisión del texto generado. En este artículo, no vamos a concentrarnos en la parte técnica y sí en las herramientas que tenemos actualmente para hacer un trabajo de estas características.
Herramientas y tecnologías para describir imágenes
Midjourney y el uso del comando /describe
Midjourney es una herramienta notable en este campo. Aunque es más conocida por sus capacidades para generar arte y visualizaciones a través de comandos de texto, posee también una función de descripción de imágenes. El comando /describe permite a los usuarios obtener una descripción textual de una imagen dada. Esta función es especialmente útil para comprender mejor el contenido visual en situaciones donde el análisis visual no es posible o práctico.
Vamos a probarlo con esta imagen:

Entramos en Midjourney, con Discord, y tecleamos el comando /describe.
Ahora subimos la imagen deseada.
El resultado llega después de un par de minutos:
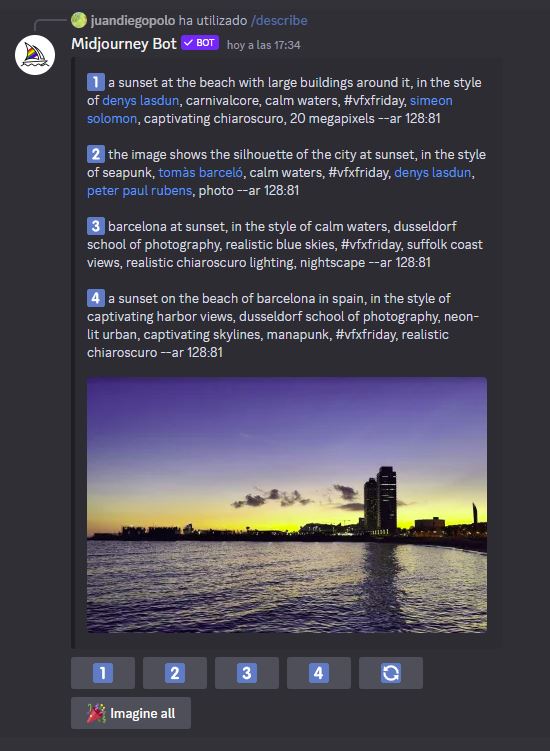
Fijaos que ofrece 4 opciones diferentes, con la posibilidad de pedir que, a partir de ese texto, genere una imagen nueva. En dos de las cuatro descripciones ha adivinado que se trata de Barcelona, y en todas ellas comenta los colores, el estilo de la foto, el sol y demás detalles de la imagen.
Otras opciones como astica.ai y Hugging Face
Además de Midjourney, tenemos la posibilidad de usar herramientas como astica.ai, que ofrece acceso a una API para integrar su inteligencia en otros programas (imaginad esta tecnología en una aplicación dentro de nuestras gafas de realidad aumentada).

En https://huggingface.co/tasks/image-to-text también tenemos una opción que permite generar descripciones más básicas, siempre a partir de la imagen que hemos enviado.

Además de opciones en web, contamos también con aplicaciones móviles que hacen la tarea, como www.captionit.ai/ , aunque en ningún momento ofrece descripciones tan detalladas como las de Midjourney
Soluciones empresariales: Google, Microsoft, IBM y Amazon
En el mundo empresarial, hay varias herramientas que realizan este trabajo, como:
- Google Cloud Vision API: esta poderosa herramienta de Google utiliza modelos de aprendizaje profundo para detectar objetos y rostros, leer texto impreso y escrito a mano, e incluso identificar atributos de imagen como etiquetas y emociones. Es ampliamente utilizada en aplicaciones empresariales y de desarrollo.
- Microsoft Azure Computer Vision API: parte de los servicios cognitivos de Microsoft Azure, esta API proporciona capacidades para analizar contenido visual en imágenes y videos. Puede etiquetar contenido, describir imágenes, detectar celebridades, identificar marcas y mucho más.
- IBM Watson Visual Recognition: esta herramienta de IBM permite a los usuarios clasificar imágenes, detectar rostros y objetos, y entrenar modelos personalizados. Es útil tanto para empresas como para desarrolladores que buscan integrar capacidades de visión por computadora en sus aplicaciones.
- Amazon Rekognition: parte de AWS, esta herramienta ofrece detección de objetos, análisis de escenas, reconocimiento de texto y reconocimiento facial. Es adecuada para una variedad de aplicaciones, desde la seguridad hasta el análisis de medios.
Aplicaciones prácticas de la IA en la descripción de imágenes
Accesibilidad para personas con discapacidad visual
Ayuda a las personas con discapacidades visuales a acceder a contenido visual. Imaginad una plataforma que de forma automática identifique el contenido de una imagen y lo describa en voz alta.
Automatización de descripciones para medios de comunicación
permite a los periodistas y creadores de contenido generar descripciones de imágenes de manera rápida y eficiente. Eso mejora el SEO, al mismo tiempo que ayuda a los programas de reconocimiento de contenido.
Mejora del SEO a través de descripciones automáticas
Al proporcionar descripciones detalladas y contextuales, estas herramientas facilitan el reconocimiento del contenido visual por parte de los motores de búsqueda. Esto mejora la clasificación y visibilidad del sitio en los resultados de búsqueda. Las descripciones automáticas de imágenes también contribuyen a mejorar la accesibilidad del sitio web. Al proporcionar texto alternativo para las imágenes, estas herramientas aseguran que el contenido visual sea accesible para todos los usuarios, incluidos aquellos con discapacidades visuales
Uso educativo para facilitar la comprensión de contenido visual
Facilita la comprensión de contenido visual para estudiantes en entornos de aprendizaje en línea.
El futuro de la IA en la descripción de imágenes
Como vemos, la descripción de imágenes mediante inteligencia artificial no solo representa un avance tecnológico, sino también una herramienta vital para mejorar la accesibilidad y la eficiencia en diversas áreas. Herramientas como Midjourney amplían las posibilidades de interacción entre humanos y máquinas, marcando un hito importante en la evolución de la IA en nuestro mundo digital. A medida que la tecnología avanza, es probable que veamos desarrollos aún más impresionantes en este campo.
Referencias
- Yildirim, Erdem. 2022. "Text-to-image generation AI in architecture". Art and architecture: theory, practice and experience, 97: 97-120. URL: https://www.researchgate.net/publication/366594739_Text-to-Image_Generation_AI_in_Architecture
- Wang, Haoran, Yue Zhang y Xiaosheng Yu. 2020. "An overview of image caption generation methods". Computational intelligence and neuroscience, 2020.3: 1-13. DOI:10.1155/2020/3062706



