
A finales de 2023, una revista científica publicó un artículo que analizaba cómo el consumo de avellanas tostadas afectaba la salud cardiovascular. Lo extraño no era el tema, sino el lugar donde apareció: una revista dedicada a cuidados de enfermería sobre el VIH. Detrás de ese sinsentido no había un error editorial, sino algo más inquietante: el dominio de esa revista había sido comprado por una organización que lo usaba para publicar estudios falsos. No se trataba de un caso aislado, sino de un ejemplo de cómo el fraude científico se ha vuelto un negocio global.
Un nuevo estudio publicado en Proceedings of the National Academy of Sciences expone el crecimiento acelerado de redes organizadas que se dedican a producir y distribuir ciencia falsa. El trabajo, liderado por Reese Richardson y Luís A. Nunes Amaral, demuestra con datos masivos que estas redes superan ya en volumen de publicaciones a la ciencia legítima. Y hay algo más preocupante. Los autores advierten que, si no se detiene esta tendencia, la inteligencia artificial podría absorber como verdad toda esa literatura contaminada, perpetuando y amplificando la mentira en futuros descubrimientos.
El ecosistema de la trampa científica
Cuando se habla de fraude científico, la mayoría piensa en un investigador aislado que falsifica datos o plagia un texto. Sin embargo, los autores del estudio revelan algo muy diferente: “grandes redes de individuos y entidades cooperan para producir fraude científico a escala”, dejando rastros visibles en la literatura científica actual.
Estas redes incluyen "fábricas de artículos" (o paper mills), que redactan y venden manuscritos a científicos que quieren engrosar su currículum sin hacer investigación real. También hay intermediarios o “brokers”, que conectan a estos compradores con revistas académicas dispuestas a publicar el material sin revisar nada. Y en muchos casos, revistas enteras han sido secuestradas o infiltradas por estas organizaciones para facilitar la publicación de basura científica.
Este fenómeno no ocurre en los márgenes del sistema, sino dentro de publicaciones indexadas en bases de datos como Scopus o Web of Science. Según el estudio, el número de artículos sospechosos de haber sido generados por fábricas de papers ya supera al de artículos retratados y a los criticados en plataformas como PubPeer.
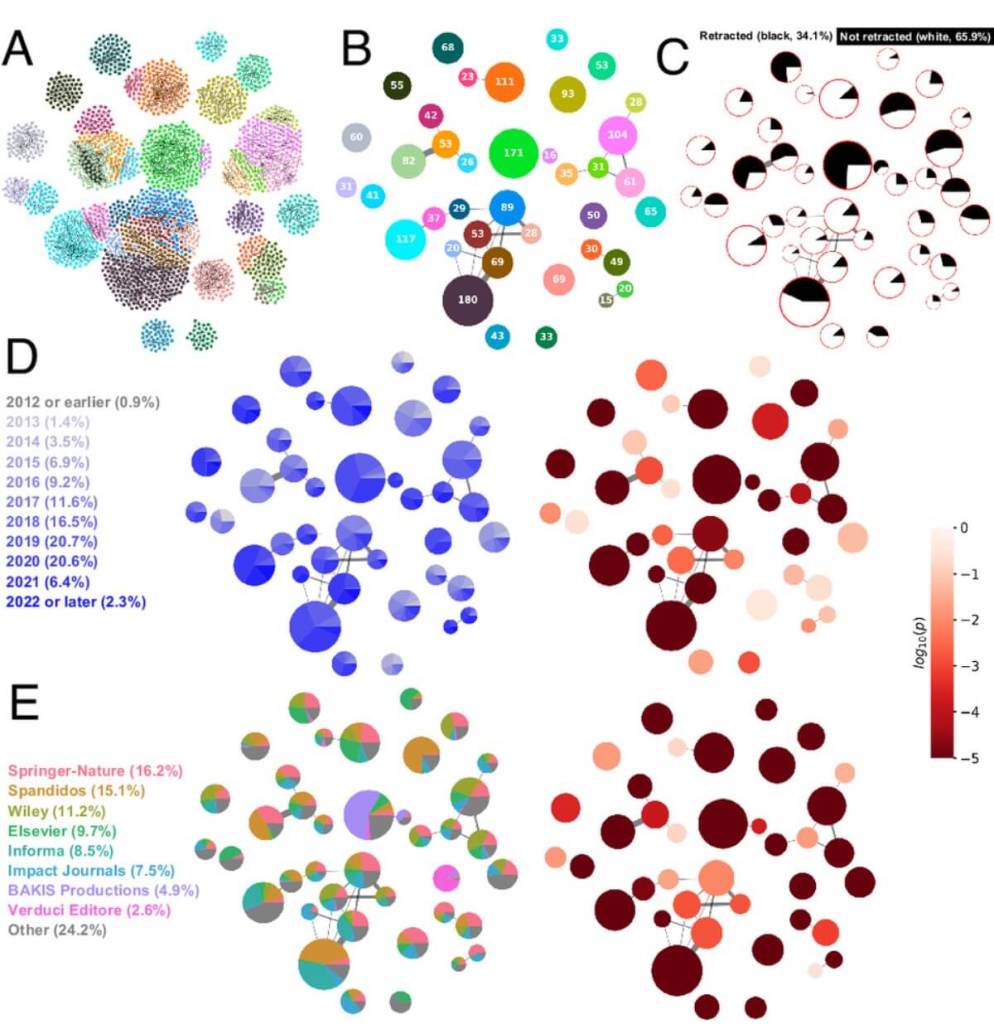
Ciencia falsa con sello de calidad
Uno de los hallazgos más inquietantes es que estas organizaciones no solo producen artículos falsos, sino que logran que parezcan legítimos. Para ello, manipulan imágenes, plagian estructuras de textos científicos reales e incluso insertan “frases torturadas”: expresiones incoherentes pero construidas con palabras científicas para pasar filtros automáticos de revisión. Algunas de estas frases resultan casi absurdas, como “determinación vegetal de consecuencias moleculares”.
Además, muchos de estos artículos incluyen autores de varios países sin conexión aparente, lo que indica que la autoría también se vende por partes. El primer autor puede pagar más que el cuarto, y si alguien quiere que su artículo se publique sin revisión, también puede pagar un extra por un proceso editorial ficticio.
Esto tiene consecuencias graves. En disciplinas como la biología molecular, se ha detectado que algunos subcampos —como los relacionados con ARN no codificante— presentan tasas de retracción de hasta el 4%, muy por encima del 0,1% habitual en campos sólidos como CRISPR. Es decir, hay disciplinas enteras donde la ciencia falsa podría haber contaminado el conocimiento de manera irreversible.

El riesgo de entrenar la inteligencia artificial con mentiras
Hasta aquí, el problema sería suficientemente alarmante. Pero el estudio da un paso más. Advierte que el crecimiento del fraude organizado coincide con el auge de modelos de lenguaje como ChatGPT, Gemini o Claude, que se entrenan a partir de textos disponibles en la red, incluyendo artículos científicos.
En el paper se advierte: "los enfoques basados en modelos de lenguaje aún no son capaces de distinguir ciencia de calidad de ciencia de baja calidad o fraudulenta", y este desafío solo empeorará a medida que el volumen de publicaciones fraudulentas aumente. En otras palabras, si no se actúa ahora, la IA —que promete sintetizar y acelerar el conocimiento— podría convertirse en un canal de amplificación de errores y falsedades.
Imagina un escenario en el que modelos entrenados con estudios falsos generen más estudios, más papers y más recomendaciones clínicas, todos basados en datos inventados. Esto no solo afectaría a la academia, sino también a la medicina, la industria farmacéutica, las políticas públicas y el conocimiento ciudadano. Lo que empieza como una trampa para escalar en la carrera investigadora, podría terminar afectando la salud y el bienestar de millones de personas.

Cómo operan estas redes: del fraude editorial al secuestro de revistas
El estudio también revela patrones de comportamiento que permiten identificar a los actores clave de estas redes. Por ejemplo, en la revista PLOS ONE, un pequeño grupo de editores aceptó el 30% de todos los artículos que luego fueron retratados, a pesar de haber manejado solo el 1,3% del total de publicaciones. Además, muchos de estos editores se enviaban artículos entre sí, como si operaran en un circuito cerrado.
Otra práctica descubierta es el “journal hopping”, que consiste en cambiar de revista cuando una de ellas ha sido descubierta o desindexada por mala praxis. Una organización llamada ARDA, por ejemplo, mantenía en su web una lista rotativa de más de 80 revistas donde garantizaba publicación, muchas de ellas ya fuera de los principales índices académicos.
Este comportamiento adaptativo demuestra que estas redes no son accidentales ni improvisadas: son estructuras resilientes, con capacidad para evadir controles y reinventarse. Como advierten los autores, "la escala de actividad en la empresa del fraude científico ya supera el alcance de las medidas punitivas actualmente implementadas".
¿Qué se puede hacer?
La respuesta no es simple, pero el estudio ofrece varias propuestas. Una de ellas es separar las funciones de detección, investigación y sanción, que actualmente recaen en los mismos actores con posibles conflictos de interés: editores, universidades o instituciones financiadoras. Otra medida clave es reforzar las plataformas de revisión post-publicación, como PubPeer, y dar respaldo legal y académico a quienes denuncian irregularidades.
Pero quizás la medida más urgente sea reconocer que el fraude ya no es marginal, sino un fenómeno estructural. Como dice el estudio, muchos investigadores jóvenes podrían estar comenzando su carrera en un entorno donde el engaño ya es la norma, y no la excepción.
Además, si se quiere evitar que la inteligencia artificial contribuya a este ciclo, es imprescindible depurar los datos con los que se entrena, aplicar filtros de calidad más exigentes y establecer criterios claros para excluir literatura contaminada.
Referencias
- Reese A. K. Richardson, Spencer S. Hong, Jennifer A. Byrne, Thomas Stoeger, Luís A. Nunes Amaral. The entities enabling scientific fraud at scale are large, resilient, and growing rapidly. Proceedings of the National Academy of Sciences, 4 de agosto de 2025. https://doi.org/10.1073/pnas.2420092122.



